
UPDATE: I've added cancellation token support to each of the database operations below, and encourage readers to
checkout the master branch to see how things look now. The methods below we're slight altered to use
a CommandDefinition that utilizes a CancellationToken passed down from the core business logic layer, and used in
place of the regular string queries we've written below.
We finally made it... our domain layer is ready to roll, and it's now time to spin up some actual application code. In our last post, we setup our initial domain layer for our favorite fictional brewery, Dappery (source code for reference). In this post, we'll build out the data access layer that will be our primary persistence mechanism into our database. We'll make use of SQL server (or Postgres) with Docker and SQLite running our unit tests within this layer. Feel free to checkout the source code on GitHub for this section for those following along.
Before we jump into the code, let's take a step back and understand why we separate our our data access layer (DAL) from the rest of our code.
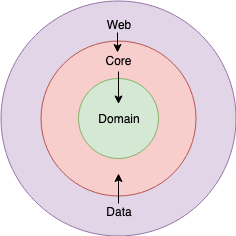
The good ole fashioned dependency graph, made famous by Robert Martin a.k.a. Dr. Bob, lays out the foundation of domain driven design (DDD). For our relatively simple application, we focus on creating four distinct layers within our application code to ensure that the layers are ultimately, by some chain of dependency, dependent on the domain layer ( effectively the 'D' in SOLID, dependency inversion). With our layers pointing inward toward our domain, we create clear boundaries within our application that deal with separate concerns:
- The web and persistence layers directly depend on our core layer
- Our core layer directly depends on the domain layer
- By association, our web and persistence, inadvertently, have a dependency on our domain layer
- The domain layer has no dependencies - all it knows, and cares about, are the entities, view models, DTOs, etc. that live inside this project and how each is related
Creating these clear boundaries of separation helps to create a modular application, with each layer isolated from one another in perfect harmony. By creating this inversion of dependency within our application, for example, our core layer does not need to know about ANY of the internal workings of the data layer - all the core layer cares about is that it can get data from a database using this actor. How the persistence layer interacts with the database is entirely abstracted from our core layer. Our data layer can change its data interaction mechanism, swap database providers, etc. and our core layer will not care as it does not concern itself with how the persistence layer works.
With that out of way, let's finally dig into the data access code we'll be writing. From the start, we said we'd be
working with Dapper for our database interaction, so let's go ahead and create a new project (a classlib in our case).
Again, I'll be using the command line, but feel free to spin up the new project in your IDE of choice:
~/Dappery/src$ dotnet new classlib -n Dappery.Data
~/Dappery/src$ dotnet sln ../Dappery.sln add Dappery.Data/Dappery.Data.csproj
With our persistence library wired up, let's go ahead and update our .csproj file within Dappery.Data to utilize
some of the new features of C# 8. Let's replace the PropertyGroup section with the following:
<PropertyGroup>
<TargetFramework>netstandard2.1</TargetFramework>
<Nullable>enable</Nullable>
<LangVersion>8.0</LangVersion>
</PropertyGroup>
Targeting netstandard2.1 allows us to utilize C# 8 features, and we'll also turn
on nullable reference types to allow the compiler
to help us catch possible null references. From our dependency graph above, we'll need to create a reference between our
data layer and our core layer. For reasons we'll see later, we'll actually need to add just a bit of skeleton code in
the core application layer for our data layer to utilize, so let's go ahead and add it now.
~/Dappery/src$ dotnet new classlib -n Dappery.Core
~/Dappery/src$ dotnet sln ../Dappery.sln add Dappery.Core/Dappery.Core.csproj
With the project added, go ahead and replace the PropertyGroup with the above for all the aforementioned reasons. Now,
back in our .csproj file in our data project, let's add the core layer as a dependency. Feel free to create the
reference using Visual Studio/Rider, as it really only boils down to adding the following line beneath
the PropertyGroup tag:
<ItemGroup>
<ProjectReference Include="..\Dappery.Core\Dappery.Core.csproj" />
</ItemGroup>
As we mentioned above, the data layer will also implicitly rely on the domain layer through its dependency on the core
layer. What this means for us, code-wise, is to add the following reference in our .csproj file in the core project:
<ItemGroup>
<ProjectReference Include="..\Dappery.Domain\Dappery.Domain.csproj" />
</ItemGroup>
With the core project referencing the domain layer, our data project will also have a reference to the domain layer without explicitly adding the reference in our data layer. Adding the domain project as a direct reference in our data project would actually have created a symmetric dependency, which we'll want to try and avoid. With the ceremony out of the way, let's talk about what we'll be adding in this layer.
The Data Layer
As this is a project revolving around Dapper for our database persistence, it's probably a good idea to bring in some patterns to help us define our intent within this layer. Rather that writing raw Dapper queries within this layer, we'll wrap our interaction with Dapper within beer and brewery repositories that will, in turn, be wrapped in a unit of work. In plain english, we'll effectively be using the Repository and Unit of Work Patterns. Alongside bringing in these patterns, a side effect of our clear application layer separation will be the creation of a ports and adapters architecture (also known as hexagonal architecture).
For our use case, our core project will offer a port in the form of data access that our data project will then fill as
the adapter. If you're unfamiliar with the repository and unit of work patterns, the specific problems they solve, and
their pros and cons, it's well worth it to take the afternoon to read up on them. For now, we'll assume you're somewhat
familiar with the pattern. With all the technical jargon out of the way, let's go ahead and create a port (effectively
an interface) within our core project, that our data project will provide the adapter for (fancy term for implementing
the interface). In Dappery.Core, go ahead and add a Data folder and the following classes:
Data/IBeerRepository.cs
namespace Dappery.Core.Data
{
using System.Collections.Generic;
using System.Threading.Tasks;
using Domain.Entities;
public interface IBeerRepository
{
Task<IEnumerable<Beer>> GetAllBeers();
Task<Beer> GetBeerById(int id);
Task<int> CreateBeer(Beer beer);
Task UpdateBeer(Beer beer);
Task<int> DeleteBeer(int beer);
}
}
Data/IBeerRepository.cs
namespace Dappery.Core.Data
{
using System.Collections.Generic;
using System.Threading.Tasks;
using Domain.Entities;
public interface IBreweryRepository
{
Task<IEnumerable<Brewery>> GetAllBreweries();
Task<Brewery> GetBreweryById(int id);
Task<int> CreateBrewery(Brewery brewery);
Task UpdateBrewery(Brewery brewery, bool updateAddress = false);
Task<int> DeleteBrewery(int breweryId);
}
}
Data/IUnitOfWork.cs
namespace Dappery.Core.Data
{
using System;
public interface IUnitOfWork : IDisposable
{
IBeerRepository BeerRepository { get; }
IBreweryRepository BreweryRepository { get; }
void Commit();
}
}
In our repositories, we've got all the ingredients for a pretty basic CRUD application. Notice that our IUnitOfWork
interface inherits from IDisposable, as it will be in charge of the database resources that we'll need to clean up
once we're finished with our data operations.
For our database provider, feel free to use whatever your preferred provider happens to be. I lay three options for us: SQL Server, Postgres, and SQLite. I'll be spinning up both a SQL Server and Postgres database, as an exercise of abstraction to really drive home the point of agnostic data access, using Postgres and SQL Server Docker images. For our unit tests, we'll be using an in-memory version of SQLite to run our tests against. If you don't feel like setting up a database for this application, don't worry... I got you. We'll generalize our database layer just enough that you'll be able to use the in-memory version of SQLite for the application as well. Since this isn't really a post about setting up database providers via Docker images, so I'll defer to this article on the official Microsoft docs on how to do so for SQL Server, and the aforementioned Docker hub for Postgres. The beauty of the architecture we've laid out so far is that no matter the database provider, our application will work with just a simple connection string change.
Before we get started implementing our repository operations, let's go ahead and setup our database. Once you've got your SQL Server, or Postgres, instance up and running, take a look at our initialization files to help create, link, and seed some test data for either provider. Go ahead and drop into a console and run the SQL for which ever provider you decide to roll with.
With our database ready to roll, let's go ahead and implement the IBeerRepository.cs and IBreweryRepository.cs
interfaces. Within Dappery.Data, let's create a Repositories folder with the following implementation classes:
Repositories/BeerRepository.cs
namespace Dappery.Data.Repositories
{
using System.Collections.Generic;
using System.Data;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Core.Data;
using Dapper;
using Domain.Entities;
public class BeerRepository : IBeerRepository
{
private readonly IDbTransaction _dbTransaction;
private readonly IDbConnection _dbConnection;
private readonly string _insertRowRetrievalQuery;
public BeerRepository(IDbTransaction dbTransaction, string insertRowRetrievalQuery)
{
_dbTransaction = dbTransaction;
_dbConnection = _dbTransaction.Connection;
_insertRowRetrievalQuery = insertRowRetrievalQuery;
}
public async Task<IEnumerable<Beer>> GetAllBeers()
{
throw new NotImplementedException();
}
public async Task<Beer> GetBeerById(int id)
{
throw new NotImplementedException();
}
public async Task<Beer> CreateBeer(Beer beer)
{
throw new NotImplementedException();
}
public async Task<Beer> UpdateBeer(Beer beer)
{
throw new NotImplementedException();
}
public async Task<int> DeleteBeer(int beerId)
{
throw new NotImplementedException();
}
}
}
Repositories/BreweryRepository.cs
namespace Dappery.Data.Repositories
{
using System.Collections.Generic;
using System.Data;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Core.Data;
using Dapper;
using Domain.Entities;
public class BreweryRepository : IBreweryRepository
{
private readonly IDbTransaction _dbTransaction;
private readonly IDbConnection _dbConnection;
private readonly string _rowInsertRetrievalQuery;
public BreweryRepository(IDbTransaction dbTransaction, string rowInsertRetrievalQuery)
{
_dbTransaction = dbTransaction;
_dbConnection = _dbTransaction.Connection;
_rowInsertRetrievalQuery = rowInsertRetrievalQuery;
}
public async Task<Brewery> GetBreweryById(int id)
{
throw new NotImplementedException();
}
public async Task<IEnumerable<Brewery>> GetAllBreweries()
{
throw new NotImplementedException();
}
public async Task<Brewery> CreateBrewery(Brewery brewery)
{
throw new NotImplementedException();
}
public async Task<Brewery> UpdateBrewery(Brewery brewery, bool updateAddress)
{
throw new NotImplementedException();
}
public async Task<int> DeleteBrewery(int breweryId)
{
throw new NotImplementedException();
}
}
}
For now, some of our imported namespaces are unused, but will be needed later when we start implementing these methods.
Next, let's add the UnitOfWork.cs implementation at the root of our Dappery.Data project:
UnitOfWork.cs
namespace Dappery.Data
{
using System;
using System.Data;
using Core.Data;
using Dapper;
using Microsoft.Data.SqlClient;
using Microsoft.Data.Sqlite;
using Npgsql;
using Repositories;
public class UnitOfWork : IUnitOfWork
{
private readonly IDbConnection _dbConnection;
private readonly IDbTransaction _dbTransaction;
public UnitOfWork(string? connectionString, bool isPostgres = false)
{
// Based on our database implementation, we'll need a reference to the last row inserted
string rowInsertRetrievalQuery;
// If no connection string is passed, we'll assume we're running with our SQLite database provider
if (string.IsNullOrWhiteSpace(connectionString))
{
_dbConnection = new SqliteConnection("Data Source=:memory:");
rowInsertRetrievalQuery = "; SELECT last_insert_rowid();";
}
else
{
_dbConnection = isPostgres ? (IDbConnection) new NpgsqlConnection(connectionString) : new SqlConnection(connectionString);
rowInsertRetrievalQuery = isPostgres ? "returning Id;" : "; SELECT CAST(SCOPE_IDENTITY() as int);" ;
}
// Open our connection, begin our transaction, and instantiate our repositories
_dbConnection.Open();
_dbTransaction = _dbConnection.BeginTransaction();
BreweryRepository = new BreweryRepository(_dbTransaction, rowInsertRetrievalQuery);
BeerRepository = new BeerRepository(_dbTransaction, rowInsertRetrievalQuery);
// Once our connection is open, if we're running SQLite for unit tests (or that actual application), let's seed some data
if (string.IsNullOrWhiteSpace(connectionString))
{
try
{
// We'll seed a couple breweries each with an address and several beers
SeedDatabase(_dbConnection);
}
catch (Exception e)
{
Console.WriteLine($"Could not seed the database: {e.Message}");
}
}
}
public IBreweryRepository BreweryRepository { get; }
public IBeerRepository BeerRepository { get; }
public void Commit()
{
try
{
_dbTransaction.Commit();
}
catch (Exception e)
{
Console.WriteLine($"Could not commit the transaction, reason: {e.Message}");
_dbTransaction.Rollback();
}
finally
{
_dbTransaction.Dispose();
}
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (disposing)
{
_dbTransaction?.Dispose();
_dbConnection?.Dispose();
}
}
private void SeedDatabase(IDbConnection dbConnection)
{
const string createBreweriesSql = @"
CREATE TABLE Breweries (
Id INTEGER PRIMARY KEY,
Name TEXT(32),
CreatedAt DATE,
UpdatedAt DATE
);
";
const string createBeersSql = @"
CREATE TABLE Beers (
Id INTEGER PRIMARY KEY,
Name TEXT(32),
BeerStyle TEXT(16),
CreatedAt DATE,
UpdatedAt DATE,
BreweryId INT NOT NULL,
CONSTRAINT FK_Beers_Breweries_Id FOREIGN KEY (BreweryId)
REFERENCES Breweries (Id) ON DELETE CASCADE
);
";
const string createAddressSql = @"
CREATE TABLE Addresses (
Id INTEGER PRIMARY KEY,
StreetAddress TEXT(32),
City TEXT(32),
State TEXT(32),
ZipCode TEXT(8),
CreatedAt DATE,
UpdatedAt DATE,
BreweryId INTEGER NOT NULL,
CONSTRAINT FK_Address_Breweries_Id FOREIGN KEY (BreweryId)
REFERENCES Breweries (Id) ON DELETE CASCADE
);
";
// Add our tables
dbConnection.Execute(createBreweriesSql, _dbTransaction);
dbConnection.Execute(createBeersSql, _dbTransaction);
dbConnection.Execute(createAddressSql, _dbTransaction);
// Seed our data
dbConnection.Execute(@"
INSERT INTO Breweries (Name, CreatedAt, UpdatedAt)
VALUES
(
'Fall River Brewery',
CURRENT_DATE,
CURRENT_DATE
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Breweries (Name, CreatedAt, UpdatedAt)
VALUES
(
'Sierra Nevada Brewing Company',
CURRENT_DATE,
CURRENT_DATE
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Addresses (StreetAddress, City, State, ZipCode, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'1030 E Cypress Ave Ste D',
'Redding',
'CA',
'96002',
CURRENT_DATE,
CURRENT_DATE,
1
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Addresses (StreetAddress, City, State, ZipCode, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'1075 E 20th St',
'Chico',
'CA',
'95928',
CURRENT_DATE,
CURRENT_DATE,
2
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'Hexagenia',
'Ipa',
CURRENT_DATE,
CURRENT_DATE,
1
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'Widowmaker',
'DoubleIpa',
CURRENT_DATE,
CURRENT_DATE,
1
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'Hooked',
'Lager',
CURRENT_DATE,
CURRENT_DATE,
1
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'Pale Ale',
'PaleAle',
CURRENT_DATE,
CURRENT_DATE,
2
);",
transaction: _dbTransaction);
dbConnection.Execute(@"
INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES
(
'Hazy Little Thing',
'NewEnglandIpa',
CURRENT_DATE,
CURRENT_DATE,
2
);",
transaction: _dbTransaction);
}
~UnitOfWork()
{
Dispose(false);
}
}
}
Okay... that's a lot of code, so let's break it down:
- In our constructor, we inject a nullable connection string (since we enabled C# 8,
strings can now be nullable), and assume that if no connection string is passed, we're probably running unit tests, or just a simple in-memory version of our application. We'll see how this injected connection string will actually be passed into ourUnitOfWorkconstructor in our API project in a later post. - Once we figure out who our database provider is, we open the connection, initialize our repositories, and seed some test data (if we're opting to use SQLite)
- We pass a the
rowInsertRetrievalQuerystring into our repositories to tell the repository how to get back the row we just added (we'll see why, exactly, we do this later) - We add some public getters to access the repositories through our
UnitOfWorkclass - We implement our
Commitmethod to try and commit the transaction to the database and rollback if anything unexpected happens - Finally, we add the disposable pattern to safely release our database resources during each transaction and destruct
our instance of the
UnitOfWork
Taking a step back let's take a look at our project structure so far:
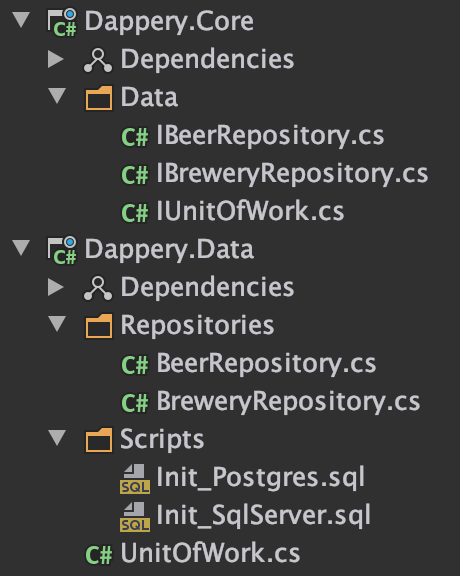
With our UnitOfWork class implemented, let's finally crank out some of our repository operations. In
our BreweryRepository.cs class, let's implement our GetAllBreweries query:
BreweryRepository.cs
public async Task<IEnumerable<Brewery>> GetAllBreweries()
{
// Grab a reference to all beers so we can map them to there corresponding breweries
var beers = (await _dbConnection.QueryAsync<Beer>(
"SELECT * FROM Beers",
transaction: _dbTransaction)).ToList();
return await _dbConnection.QueryAsync<Brewery, Address, Brewery>(
// We join with addresses as there's a one-to-one relation with breweries, making the query a little less intensive
"SELECT * FROM Breweries br INNER JOIN Addresses a ON a.BreweryId = br.Id",
(brewery, address) =>
{
// Map the address to the brewery
brewery.Address = address;
// Map each beer to the beer collection for the brewery during iteration over our result set
if (beers.Any(b => b.BreweryId == brewery.Id))
{
foreach (var beer in beers.Where(b => b.BreweryId == brewery.Id))
{
brewery.Beers.Add(beer);
}
}
return brewery;
},
transaction: _dbTransaction);
}
Let's breakdown what's going on in this query:
- First, we grab a reference to all the beers in our database so we can map each beer up to its corresponding brewery
- Next, we query the brewery table and do a simple join on the address table
- Finally, once we have our result set, we set each brewery's address to the joined address, and add all the beers to the data model (if any exist)
Again, I'm not an expert with Dapper, so I'm sure there's some optimization to be done here. As this is just us exploring Dapper, this will suffice for now. For example, rather than performing two separate queries to get our associated beers that map to their breweries, we could flat query all the beers using some nested sub queries. A few issues arise, however, as there are many beers to one brewery, so this might not be the most viable solution - simply just food for thought.
Syntactically, Dapper offers some nice ADO.NET-like methods to help us write our queries and commands. We see that
the QueryAsync<Brewery, Address, Brewery> method sets up the expectation of what this query returns - the first two
generic types tell Dapper that this is a joined query that will contain two of our entities, with the third being the
entity Dapper should perform the mapping for and ultimately return. We see that one of the parameters in this call is an
expression function (the Func<Brewery, Address>) that we use to add the reference to the address for the brewery and
add all the beers.
Let's jump over to our beer repository and implement the GetAllBeers method:
BeerRepository.cs
public async Task<IEnumerable<Beer>> GetAllBeers()
{
// Retrieve the addresses, as this is a nested mapping
var addresses = (await _dbConnection.QueryAsync<Address>(
"SELECT * FROM Addresses",
transaction: _dbTransaction)).ToList();
return await _dbConnection.QueryAsync<Beer, Brewery, Beer>(
@"SELECT b.*, br.* FROM Beers b INNER JOIN Breweries br ON br.Id = b.BreweryId",
(beer, brewery) =>
{
// Map the brewery that Dapper returns for us to the beer
brewery.Address = addresses.FirstOrDefault(a => a.BreweryId == brewery.Id);
beer.Brewery = brewery;
return beer;
},
transaction: _dbTransaction
);
}
Again, taking a look at what we've done above, this query is pretty straight forward: we retrieve the brewery addresses, and then separately query the beers table with the breweries table and map each brewery's address during iteration over our result set. Looking good so far, let's bust out those retrieve by ID methods for both entities:
BreweryRepository.cs
public async Task<Brewery> GetBreweryById(int id)
{
var beersFromBrewery = (await _dbConnection.QueryAsync<Beer>(
@"SELECT * FROM Beers WHERE BreweryId = @Id",
new {Id = id},
_dbTransaction)).ToList();
return (await _dbConnection.QueryAsync<Brewery, Address, Brewery>(
@"SELECT br.*, a.* FROM Breweries br INNER JOIN Addresses a ON a.BreweryId = br.Id WHERE br.Id = @Id",
(brewery, address) =>
{
// Since breweries have a one-to-one relation with address, we can initialize that mapping here
brewery.Address = address;
// Add each beer from the previous query into the list of beers for the brewery
if (beersFromBrewery.Any())
{
foreach (var beer in beersFromBrewery)
{
brewery.Beers.Add(beer);
}
}
return brewery;
},
new { Id = id },
_dbTransaction)).FirstOrDefault();
}
BeerRepository.cs
public async Task<Beer> GetBeerById(int id)
{
// Retrieve the beer from the database
var beerFromId = (await _dbConnection.QueryAsync<Beer, Brewery, Beer>(
@"SELECT b.*, br.* FROM Beers b
INNER JOIN Breweries br ON br.Id = b.BreweryId
WHERE b.Id = @Id",
(beer, brewery) =>
{
beer.Brewery = brewery;
return beer;
},
new { Id = id },
_dbTransaction)).FirstOrDefault();
// Return back to the caller if no beer is found, let the business logic decide what to do if we can't the specified beer
if (beerFromId == null)
{
return null;
}
// Map the address to the beer's brewery
var address = await _dbConnection.QueryFirstOrDefaultAsync<Address>(
@"SELECT * FROM Addresses WHERE BreweryId = @BreweryId",
new { BreweryId = beerFromId.Brewery?.Id },
_dbTransaction);
// Set the address found in the previous query to the beer's brewery address, if we have a brewery
if (beerFromId.Brewery != null)
{
beerFromId.Brewery.Address = address;
}
// Let's add all the beers to our brewery attached to this beer
var beersFromBrewery = await _dbConnection.QueryAsync<Beer>(
@"SELECT * FROM Beers WHERE BreweryId = @BreweryId",
new { beerFromId.BreweryId },
_dbTransaction);
// Lastly, let's add all the beers to the entity model
foreach (var beer in beersFromBrewery)
{
beerFromId.Brewery?.Beers.Add(beer);
}
return beerFromId;
}
Pretty straight forward - the only addition here is the use of Dapper's QueryFirstOrDefaultAsync<Beer>() method, which
we conveniently use to retrieve the address of the beer's brewery in question, set the brewery address, and finally
attach all the beers we have in the database to the brewery. Again, I'm no Dapper expert by any means, so I'm sure we
could optimize this query quite a bit. For the EF Core fellows in the crowd, the above would be equivalent to
a .Include().ThenInclude() query, and while I'm sure we could combine some of the above queries, I break up each query
for readability, as well as debug-ability. Next, let's add our create and update commands for each repository:
BeerRepository.cs
public async Task<int> CreateBeer(Beer beer)
{
// From our business rule we defined, we'll assume the brewery ID is always attached to the beer
var beerToInsertSql = new StringBuilder(@"INSERT INTO Beers (Name, BeerStyle, CreatedAt, UpdatedAt, BreweryId)
VALUES (@Name, @BeerStyle, @CreatedAt, @UpdatedAt, @BreweryId)");
// Let's insert the beer and grab its ID
var beerId = await _dbConnection.ExecuteScalarAsync<int>(
beerToInsertSql.Append(_insertRowRetrievalQuery).ToString(),
new
{
beer.Name,
beer.BeerStyle,
beer.CreatedAt,
beer.UpdatedAt,
beer.BreweryId
},
_dbTransaction);
// Finally, we'll return the newly inserted beer Id
return beerId;
}
BeerRepository.cs
public async Task UpdateBeer(Beer beer)
{
// Our application layer will be in charge of mapping the new properties to the entity layer,
// as well as validating that the beer exists, so the data layer will only be responsible for
// inserting the values into the database; separation of concerns!
await _dbConnection.ExecuteAsync(
@"UPDATE Beers SET Name = @Name, BeerStyle = @BeerStyle, UpdatedAt = @UpdatedAt, BreweryId = @BreweryId WHERE Id = @Id",
new
{
beer.Name,
beer.BeerStyle,
beer.UpdatedAt,
beer.BreweryId,
beer.Id
},
_dbTransaction);
}
BreweryRepository.cs
public async Task<int> CreateBrewery(Brewery brewery)
{
// Grab a reference to the address
var address = brewery.Address;
var breweryInsertSql =
new StringBuilder(@"INSERT INTO Breweries (Name, CreatedAt, UpdatedAt) VALUES (@Name, @CreatedAt, @UpdatedAt)");
// Let's add the brewery
var breweryId = await _dbConnection.ExecuteScalarAsync<int>(
breweryInsertSql.Append(_rowInsertRetrievalQuery).ToString(),
new { brewery.Name, brewery.CreatedAt, brewery.UpdatedAt },
_dbTransaction);
// One of our business rules is that a brewery must have an associated address
await _dbConnection.ExecuteAsync(
@"INSERT INTO Addresses (StreetAddress, City, State, ZipCode, CreatedAt, UpdatedAt, BreweryId)
VALUES (@StreetAddress, @City, @State, @ZipCode, @CreatedAt, @UpdatedAt, @BreweryId)",
new
{
address.StreetAddress,
address.City,
address.State,
address.ZipCode,
address.CreatedAt,
address.UpdatedAt,
BreweryId = breweryId
},
_dbTransaction);
return breweryId;
}
BreweryRepository.cs
public async Task UpdateBrewery(Brewery brewery, bool updateAddress)
{
// Again, we'll assume the brewery details are being validated and mapped properly in the application layer
await _dbConnection.ExecuteAsync(
@"UPDATE Breweries SET Name = @Name, UpdatedAt = @UpdatedAt WHERE Id = @Id",
new
{
brewery.Name,
brewery.UpdatedAt,
brewery.Id
},
_dbTransaction);
if (brewery.Address != null && updateAddress)
{
// Again, we'll assume the brewery details are being validated and mapped properly in the application layer
// For now, we won't allow users to swap breweries address to another address
await _dbConnection.ExecuteAsync(
@"UPDATE Addresses SET StreetAddress = @StreetAddress, City = @City, ZipCode = @ZipCode, State = @State, UpdatedAt = @UpdatedAt WHERE Id = @Id",
new
{
brewery.Address.StreetAddress,
brewery.Address.City,
brewery.Address.ZipCode,
brewery.Address.State,
brewery.Address.UpdatedAt,
brewery.Address.Id
},
_dbTransaction);
}
}
In our commands above, notice the absence of checking the entities passed in for validity and the absence of exceptions - that's intentional! Our data access layer is responsible for one thing, and one thing only: database interaction. That's it; no more, no less. Any checking for request data, throwing exceptions, mapping entities, etc. will all be done in our core business layer, as that is its intended purpose. By keeping our persistence layer as simple as possible and giving it a single responsibility in the form of database access, we've create a boundary in this layer and between all other cross-cutting concerns.
In our create operations above, we also pass back the last effected row ID (in the case of SQLite and SQL Server) so that we can pass that back to the business layer. There's a few reasons for doing this:
- By passing back the row ID to the core business layer, we allow our callers to simply query the database again with the inserted entity's row ID for a lightning fast retrieve, should the layer see a need for it (we will be doing this, for example)
- With the row ID being returned, the business layer can simply go about its business doing any business logic it needs to validate entities, link relations, etc.
- Performing this passing of the last effected row ID in the persistence layer is (arguably) the easiest way to do this type of operation, as we are talking directly to the database in the layer and can easily access the row via SQL rather than having our callers perform a more intensive text based search, for example, in our database
So why wouldn't we want to do this? Well, there's one big reason where this may become an issue - concurrency. In a real world production database, there are hundreds of thousands (even millions at the enterprise scale) transactions being performed against database everyday. In doing so, there is a non-zero probability that when retrieving the last effected row ID, we could get back the ID of another entity that just so happened to be inserted, or updated, at that very moment as well. In practice, our implementation may not be the best approach in a high traffic production environment, but for our relatively simple application, it'll make do.
I should mention that, again, as we're simply just exploring Dapper in our example application, there's still a ton of room for improvement here. Between our query optimization and testability of this layer, there's a lot of refactoring we could do here to make our code faster and more reliable. For our use case, we'll keep our queries and commands simple for now (as I'm in the same boat as many you - in no way a Dapper expert).
Lastly, we'll top off our CRUD operations with the implementation of each delete method:
BreweryRepository.cs
public async Task<int> DeleteBrewery(int breweryId)
{
// Because we setup out database providers to cascade delete on parent entity removal, we won't have to
// worry about individually removing all the associated beers and address
// NOTE: Because we don't directly expose CRUD operations on the address table, we'll validate the cascade
// remove directly in the database for now
return await _dbConnection.ExecuteAsync(
@"DELETE FROM Breweries WHERE Id = @Id",
new { Id = breweryId },
_dbTransaction);
}
BeerRepository.cs
public async Task<int> DeleteBeer(int beerId)
{
// Our simplest command, just remove the beer directly from the database
// Validation that the beer actually exists in the database will left to the application layer
return await _dbConnection.ExecuteAsync(
@"DELETE FROM Beers WHERE Id = @Id",
new { Id = beerId },
_dbTransaction);
}
Our delete operations are simple as can be, just deleting rows from our database (with no validation being performed, as that is an exercise for the business layer). No magic here.
And with that... we've finally completed our persistence layer! We've laid the foundation for our core business layer to now tap into a database to persist and query data, alongside allowing the option for three difference database providers. Not a bad day's work, if I do say so myself. As a side note, that was a lot of code we just cranked out. Let's recap exactly what we did in this post:
- We bootstrapped our
Dappery.DataandDappery.Coreprojects - We implemented CRUD operations using Dapper wrapped within a couple repositories, and all brought together by a unit of work
- We kickstarted our databases in the form of SQLite, SQL Server, and Postgres, leaving the choice up to the consumer by simply changing a connection string
On a rainy day, I'll sit down and guide us through setting up Docker images for database providers and integrating them with our .NET Core applications. For now, I'll leave it as an exercise for the reader on how to do so.
In our next post, we'll create a simple test project that will help bulletproof our code within this layer, so that any change we decide to make in the future, we'll be able to safely validate that it's still doing its job. After that, we'll implement our business layer that will contain our core CQRS architecture with the help of libraries in MediatR and FluentValidation. Check out the source code here to see where we're at so far. Until next time, amigos!